This article was last updated on <span id="expire-date"></span> days ago, the information described in the article may be outdated.
前言
目前有不少在虚拟环境中的深度感知的研究。但是这些研究大多都是通过一些主观的实验来获得相对客观的数据来进行分析。这些研究大多缺乏说服力。
比如这篇《Distance perception with a video see-through head-mounted display》。他们研究深度感知的方法居然是使用盲掷的方法来估计受试者的深度感知。很难说这些实验有什么说服力。尽管他们的数据也不错,但是这是通过大量的人(20+)和大量的时间才能规避掉相对主观的数据。总之就是相对麻烦。
我前段时间看到了名为《Perceptual self‑position estimation based on gaze tracking in virtual reality》的论文。该论文提出了一种不依赖受试者主观感受的基于深度感知的自我定位方法。这种方法大约就是分别获得左右眼的视线,随后将获取视线的公垂线的中点作为估计的视线焦点。由此计算出的焦点距离就是感知的深度。通过这种方法计算出来的深度是可以量化的,以后多数的研究就不再需要通过丢沙包等主观实验的方法来获得深度感知的数据了。
由于组会的原因,我需要作这篇论文的报告。于是为了让我的工作量看上去大一点。因此,我想要使用论文中提到的算法进行一些分析。毕竟在我粗略的观察下,这个方法似乎并不难。
尽管论文中提到了一些有关相机标定的知识,而且其作用仅仅是用来估计虚拟目标的位置。这种估计似乎完全没有意义。因此在虚拟世界中,对于目标和自身的空间坐标完全是已知的,并没有什么估计的需求。但论文作者仍然用了估计的方法,并且还会进一步造成误差。不知道他们是何用意。总之,接下去我先大致介绍一下这篇论文。随后给出我的实现和实验。
论文介绍
这篇论文Perceptual self‑position estimation based on gaze tracking in virtual reality发布于2021年的Virtual Reality。似乎是2区的期刊。
研究背景
在虚拟环境(VE)中,虚拟相机可以模拟用户的眼睛,获取画面,并通过左右双屏显示在用户眼前。理论上,虚拟相机的各类参数应该与人眼相同,而且显示器显示的立体画面应当显示所需的深度信息。即:人类视觉系统(HVS)的深度感知在VR环境中保持不变。
然而,由于技术所限,每个用户的眼睛状态不同,显示无法还原所有的深度信息。导致在VR环境中,深度感知存在偏差。目前除了专门研究深度感知的研究,大部分的工作都没有考虑感知深度和实际深度之间的差异。即便是研究深度感知的相关论文,他们大部分也还是依靠被试者的主观判断来获得实验数据。
比如之前提到的《Distance perception with a video see-through head-mounted display》。就是通过盲掷的手法来间接衡量深度感知的。这种实验耗时耗力,而且缺乏说服力。
已经有不少的研究者发现,用户在虚拟环境中普遍低估了深度。比如Pollock等人的工作就认为,用户在虚拟环境中的深度感知是实际距离的50~80%[1],Kelly等人的工作也支持这一结论,他们的结果是71%[2]。
给本文的研究者提供较大帮助的是Mujahidin等人的研究[3]。他们提出了一种通过视线相交来估计视线深度的方法。视线的相交是通过估计3D空间中左眼和右眼视线之间最近线段(中垂线)的中点来实现的。
如下图所示:
$$
P^W表示用户在真实空间中的位置。
P^V 表示虚拟空间中的虚拟相机位置,代表用户的眼睛.
E^V 代表眼睛中心.
由于在虚拟环境中的深度感知会出现偏差,因此用P_H^V来表示虚拟环境中的位置.
本文提出的方法旨在计算出准确的P_H^V 来代替P^V ,减少深度感知误差带来的不适感。
$$
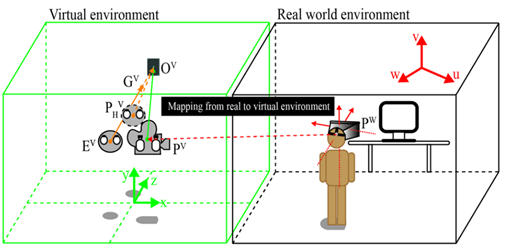
该文的研究前提是真实空间和虚拟空间进行Mapping是绝对准确的。
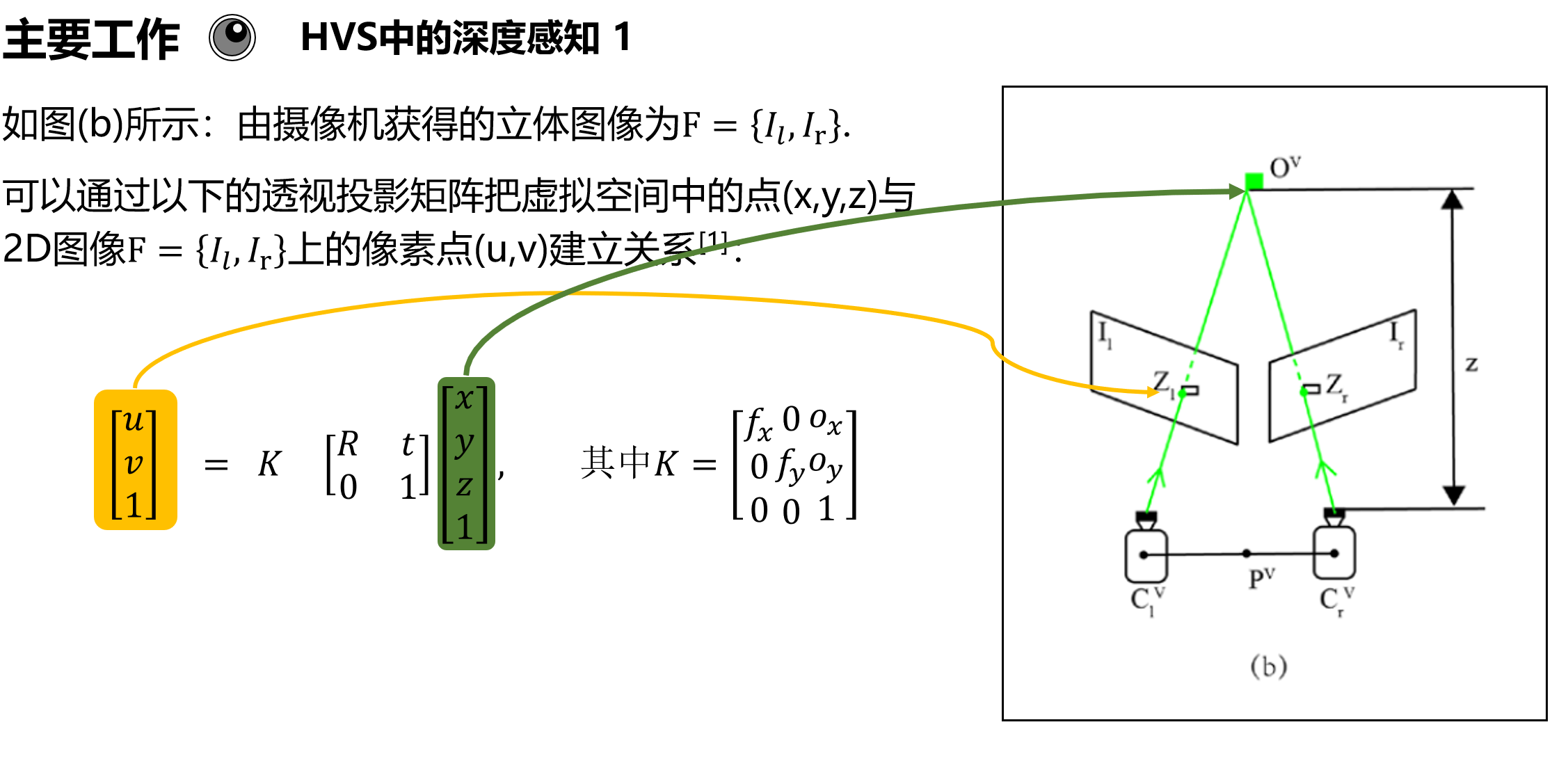

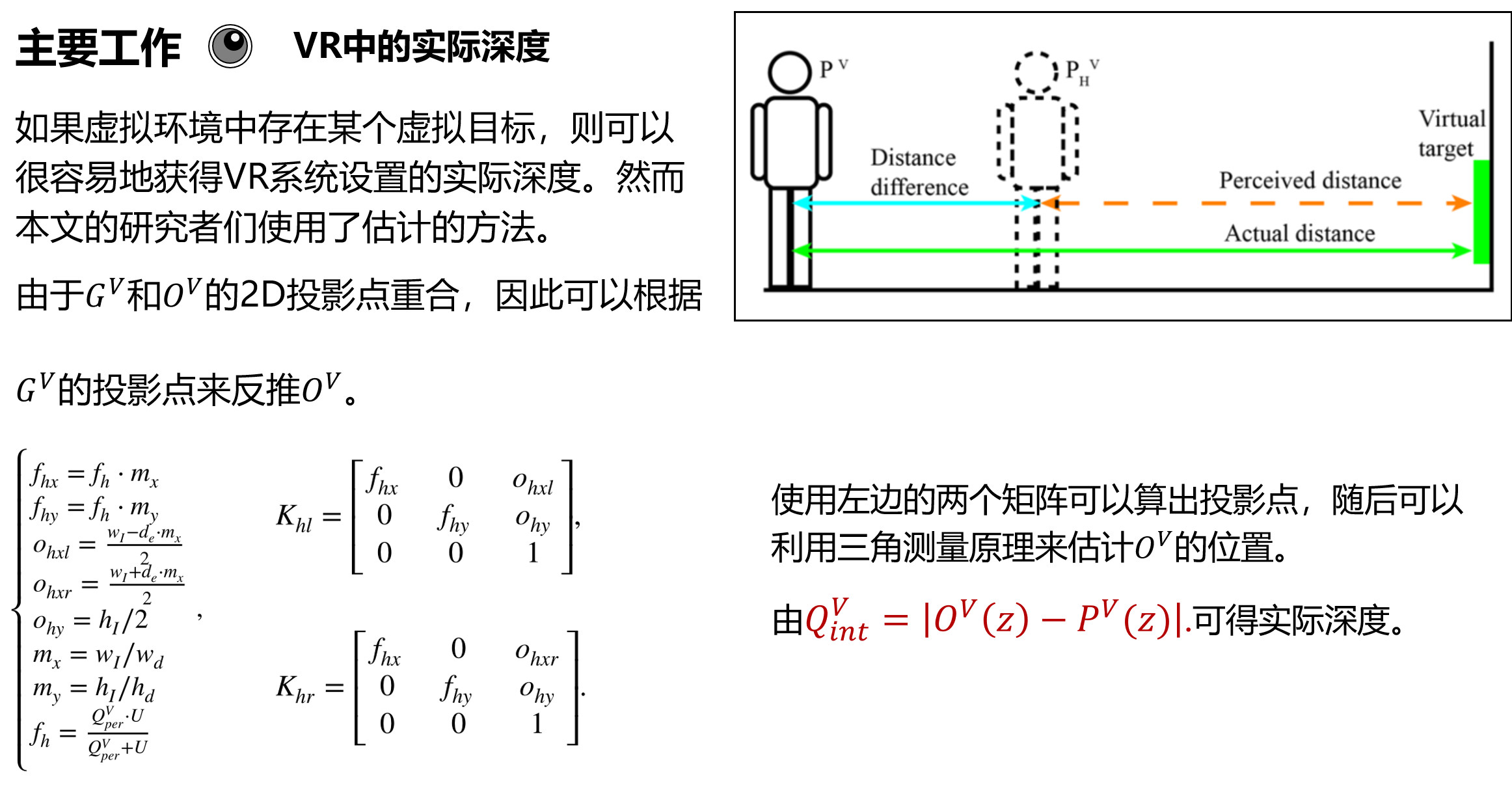
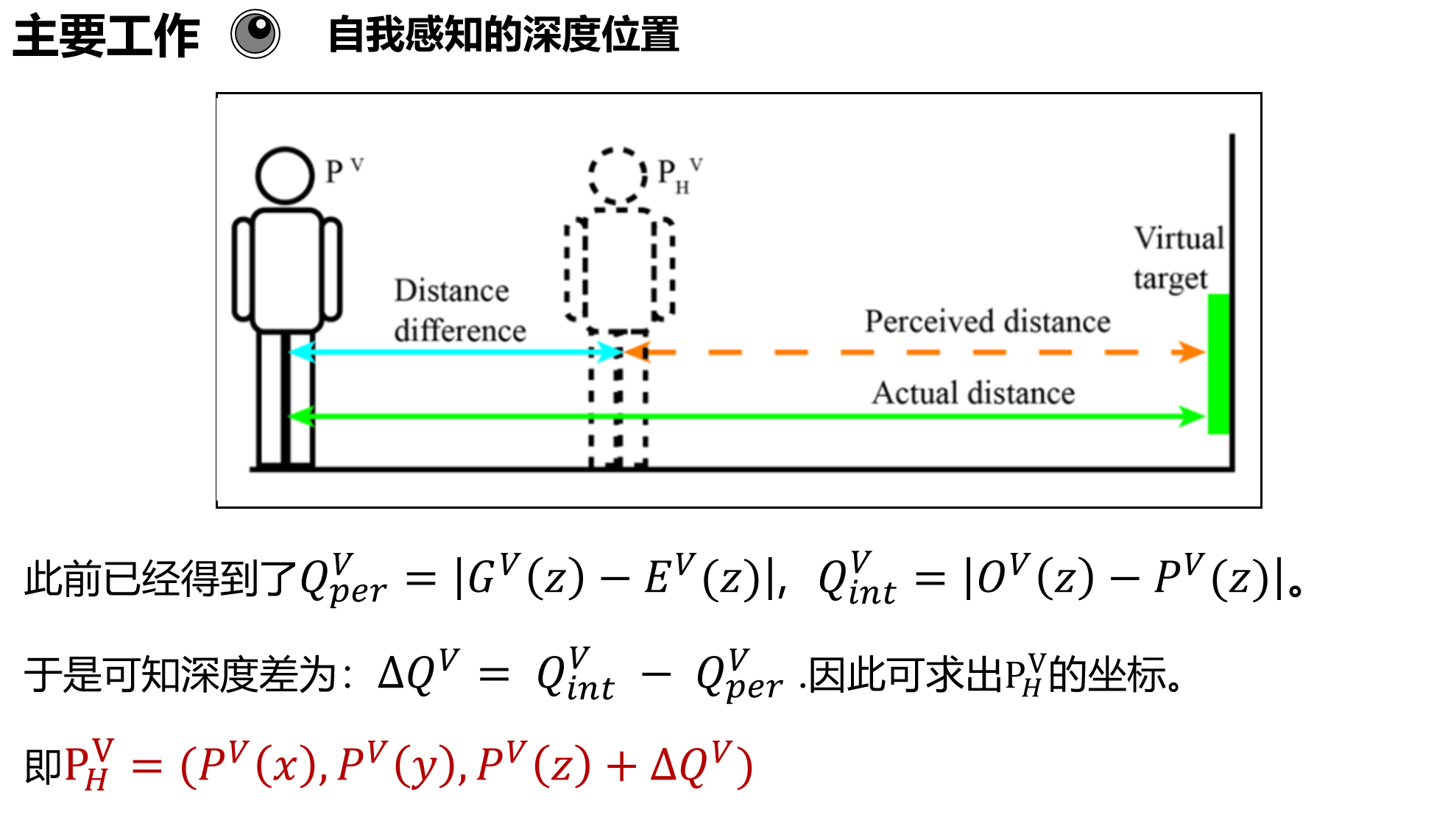
为了省事我就直接放PPT的截图了。
验证实验
在了解该方法后,我就打算先写个小实验来证明它。但是第一步就是要获得双眼的视线。我一开始在HTC VIVE EYE PRO官方提供的SDK文档中进行了查找,找到了视线的数据。但是这个视线的数据是双眼混合的,尽管数据里面有左右眼各自的视线数据,但是我却不会写。不过我经过一番查找,在官方论坛的一个Bug报告帖中,看到某人为了说明官方插件中双目视线存在Bug而写的代码。这段代码恰好能够可视化双眼的视线。这帮了我大忙,可以说该实验完成了大部分。接下去就是根据论文中的方法来算出空间直线的公垂线的中点了。
这也是比较困难的。一开始我试图自己写。但是编码能力不过关。导致我虽然看到了数学的解法,但是无法用编程的方法写出来。后来经过一番查找,发现C++的一个开源库中提供了这个方法。因此我直接将C++代码转写成C#代码,经实验。确实可行。
1 | public void lineToLineSegment(Vector3 linea,Vector3 pointInA,Vector3 lineb,Vector3 pointInB,out Vector3 pointA,out Vector3 pointB){ |
总之,以上就是编码上遇到的问题了。随后我做了点小实验来验证该方法的可行性。
我先是设计了如下图的三个场景,用来表示无深度线索的深度感知、有深度线索的深度感知、将距离腿远后的深度感知情况。其中,将深度推远的意义在于,尽管我们算出了深度差,但是由于现实世界和虚拟世界的角色位置是映射起来的。如果我们直接将虚拟人物向前平移来减少深度感知的误差,那么反而会造成更大的不适感。因此,可以反向思考,即将物体推远。即虚拟世界中的1.4M = 1M 。通过这种方式来缓解不适感。理论上,这种方法会有用。论文的作者的数据也显示,推远距离后不适感降低了。但是我的验证实验却没有得到类似的结果。或者说几乎没影响。
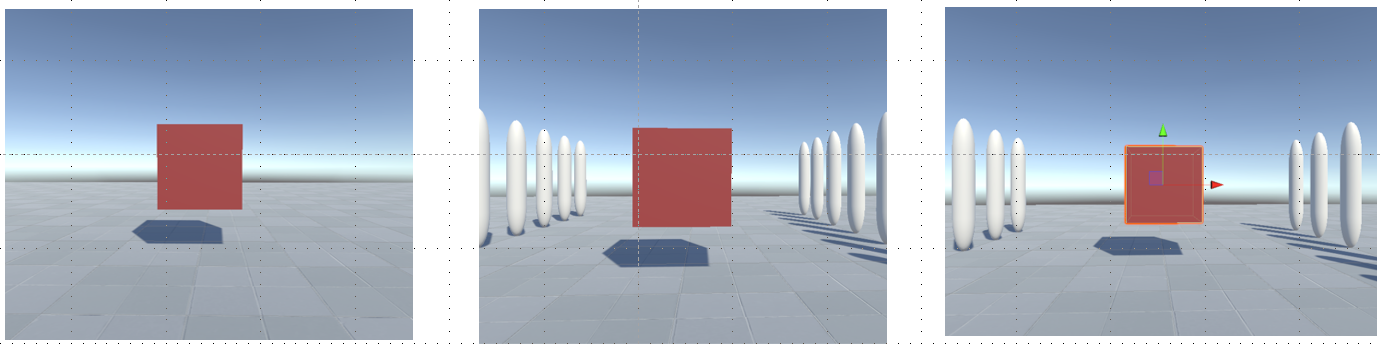
我带着头盔盯着红色的方块,然后记录下所有的感知距离。当然,我直接排除掉了一些很明显错误的数据来减少误差。本文作者是通过凝视时间来排除误差的,我懒得做了。
再获得数据后,我再把每个数据都画出图表。如下图。
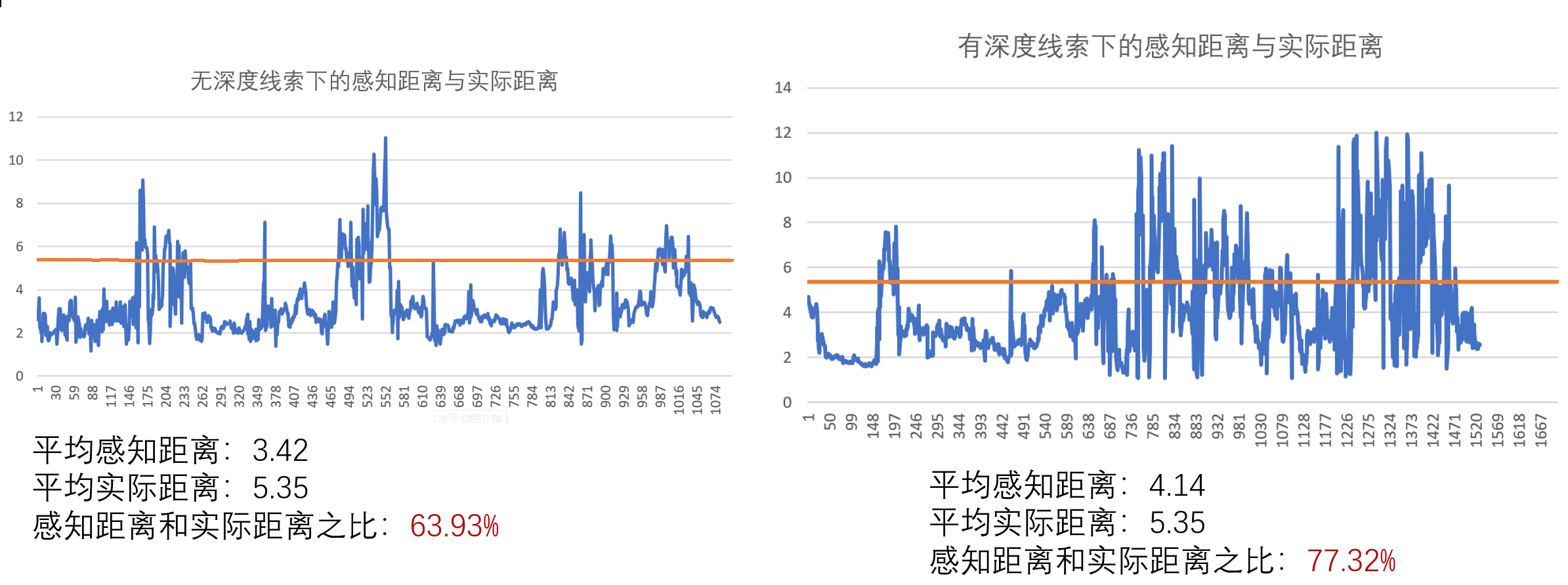
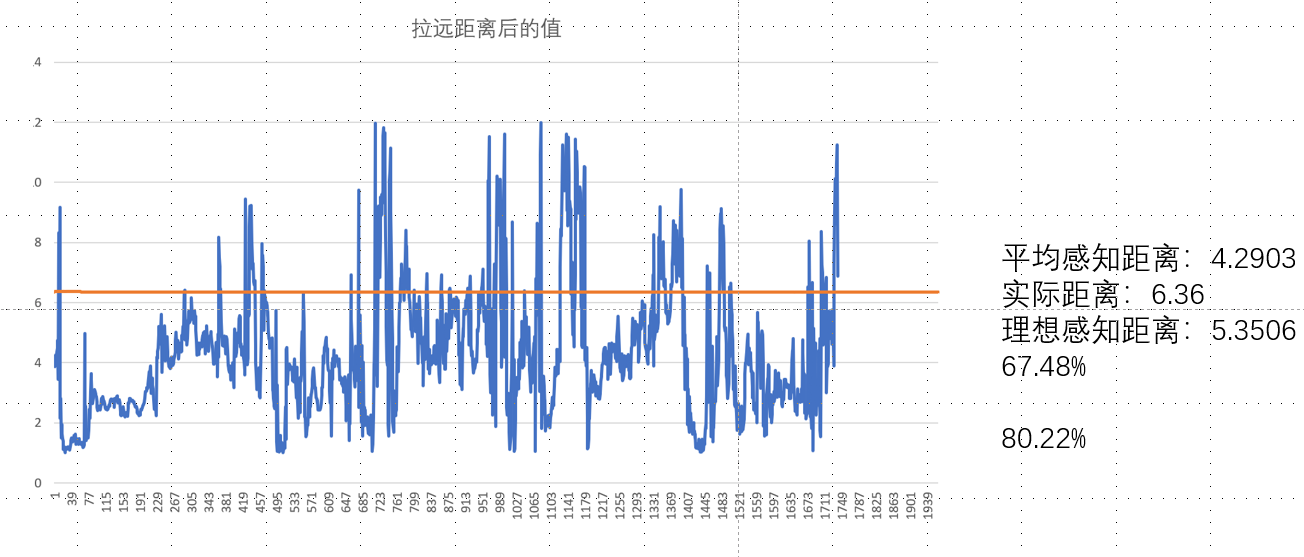
可以发现,在有深度线索的情况下,确实深度感知的误差会减少。但是推远物体后,提升并不明显。知识从77.32%提升到了80.22%。实际差距更是直接吊打了67.48%。不知道这种情况是什么原因。
还有,从记录下来的数据可以发现,我的视线交点似乎已知在移动,而且变化的还挺剧烈的。这也许是因为我在做实验的时候仍然能够看到可视化的双眼实现和中垂线。导致我下意识地聚焦在这些线条上导致的错误数据。
总之,这个实验还有可以改进的地方。这个方法似乎确实可以用来客观衡量深度感知。只是能否将其用上就是一个未知数了。